
▸ Regularization :
 Quiz - Regularization | Andrew NG")
Recommended Machine Learning Courses:
- Coursera: Machine Learning
- Coursera: Deep Learning Specialization
- Coursera: Machine Learning with Python
- Coursera: Advanced Machine Learning Specialization
- Udemy: Machine Learning
- LinkedIn: Machine Learning
- Eduonix: Machine Learning
- edX: Machine Learning
- Fast.ai: Introduction to Machine Learning for Coders
- You are training a classification model with logistic regression. Which of the following statements are true? Check all that apply.
- Introducing regularization to the model always results in equal or better performance on the training set.
- Introducing regularization to the model always results in equal or better performance on examples not in the training set.
- Adding a new feature to the model always results in equal or better performance on the training set.
- Adding many new features to the model helps prevent overfitting on the training set.
- Suppose you ran logistic regression twice, once with
, and once with
. One of the times, you got parameters
, and the other time you got
. However, you forgot which value of
corresponds to which value of
. Which one do you think corresponds to
-
When
-
-
- Suppose you ran logistic regression twice, once with
, and the other time you got
. However, you forgot which value of
-
-
When
-
- Which of the following statements about regularization are true? Check all that apply.
- Using a very large value of
- Because logistic regression outputs values
, its range of output values can only be “shrunk” slightly by regularization anyway, so regularization is generally not helpful for it.
- Consider a classification problem. Adding regularization may cause your classifier to incorrectly classify some training examples (which it had correctly classified when not using regularization, i.e. when λ = 0).
- Using too large a value of λ can cause your hypothesis to overfit the data; this can be avoided by reducing λ.
- Using a very large value of
- Which of the following statements about regularization are true? Check all that apply.
- Using a very large value of
- Because logistic regression outputs values
- Because regularization causes J(θ) to no longer be convex, gradient descent may
not always converge to the global minimum (when λ > 0, and when using an
appropriate learning rate α). - Using too large a value of λ can cause your hypothesis to underfit the data; this can be avoided by reducing λ.
- Using a very large value of
- In which one of the following figures do you think the hypothesis has overfit the training set?
- Figure:
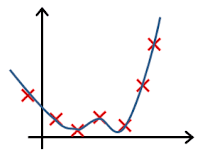
- Figure:

- Figure:
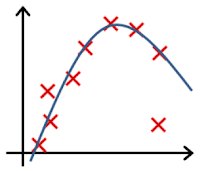
- Figure:

- Figure:
Check-out our free tutorials on IOT (Internet of Things):
- In which one of the following figures do you think the hypothesis has underfit the training set?
- Figure:
- Figure:

- Figure:
- Figure:
- Figure:
Click here to see solutions for all Machine Learning Coursera Assignments.
&
Click here to see more codes for Raspberry Pi 3 and similar Family.
&
Click here to see more codes for NodeMCU ESP8266 and similar Family.
&
Click here to see more codes for Arduino Mega (ATMega 2560) and similar Family.
Feel free to ask doubts in the comment section. I will try my best to answer it.
If you find this helpful by any mean like, comment and share the post.
This is the simplest way to encourage me to keep doing such work.
&
Click here to see more codes for Raspberry Pi 3 and similar Family.
&
Click here to see more codes for NodeMCU ESP8266 and similar Family.
&
Click here to see more codes for Arduino Mega (ATMega 2560) and similar Family.
Feel free to ask doubts in the comment section. I will try my best to answer it.
If you find this helpful by any mean like, comment and share the post.
This is the simplest way to encourage me to keep doing such work.
Thanks & Regards,
- APDaga DumpBox
- APDaga DumpBox
Why 1. cannot be D)? I could not see any difference between example and training set.
ReplyDeleteI mean alternative B (instead of D)
DeleteI couldn't understand what exactly your are trying to ask?
DeleteAdding many new features will overfit the data instead of preventing overfitting
Delete@Unknown True. Agreed.
DeleteThat's the reason Why D is the wrong Answer for Q1.
Hi,
DeleteYeah you are right, Adding many new features can cause overfitting and regularization such as L1 and L2 are actually pushing effects of some features close to zero. I am not sure why its not considered as correct answer in this quiz